Published: 2023-01-04 | 8 min read
- Slack
- Data
- Snowflake
- Hightouch
- GraphQL
Leveraging Slack data in user facing products
1. Why are communities still on Slack?
While Slack’s primary target group are business, it has been frequently adopted as a messaging tool by communities. Initially, this was largely due to limited availability or subpar UX of alternatives. Over the time, many other messaging tools, such as Discord, have emerged that have been catering specifically to communities. While those alternatives might be a better fit in terms of the feature set and pricing models, many communities haven’t made that switch. This is especially the case for those, whose members tend to use Slack in their workplace. Having to use another messaging tool is often a meaningful barrier that would’ve led to a drop off in the engagement.
2. Leveraging Slack data at On Deck
Since its early days, Slack has been an important component of the user experience for On Deck community members. These are typically startup founders, investors and employees, and the majority of those organizations use Slack as their primary messaging tool. While a lot of core interactions happen via our Community Platform, Slack is still an important channel that our users connect through. Each program has its own workspace and some channels are shared across the workspaces.
Since so much activity happens within Slack, it becomes important to be able to monitor that usage over time in order to track the community health and engagement outside of our Community Platform. This data can also be used to extract insights that will inform decision making and future product roadmaps.
While Slack offers some basic analytics through its web UI and APIs, they are rather basic. This is why we’ve built a custom pipeline (which is orchestrated using Prefect) to ingest public channels Slack messages into our data warehouse (Snowflake). This involves several steps
- Fetch relevant messages and related events
- Parse the fetched content, extract relevant information and transform into a desired format
- Insert rows into relevant tables in Snowflake
This allows our product, engineering and other business users to generate valuable insights about Slack usage at On Deck using SQL and via pre-configured dashboards. Without it, we would have a major blind spot around a key component of the user journey. Being able to analyze Slack usage, allows us to use Slack to experiment with new product ideas before we decide to build them out as part of the Community Platform and to generate ideas from organic behavior that emerges over the time.
One of the most popular use cases that have emerged on Slack have been asks channels, where community members can post questions to get input from others. Having more than 10,000 asks is a great base that we can now use to design this product as part of the Community Platform.
While using Slack data for analytics, reporting and generating insights is tremendously valuable by itself, we’ve felt there is also an opportunity surface this data back to the users on the Community Platform.
3. Bringing Slack activity data to user profiles
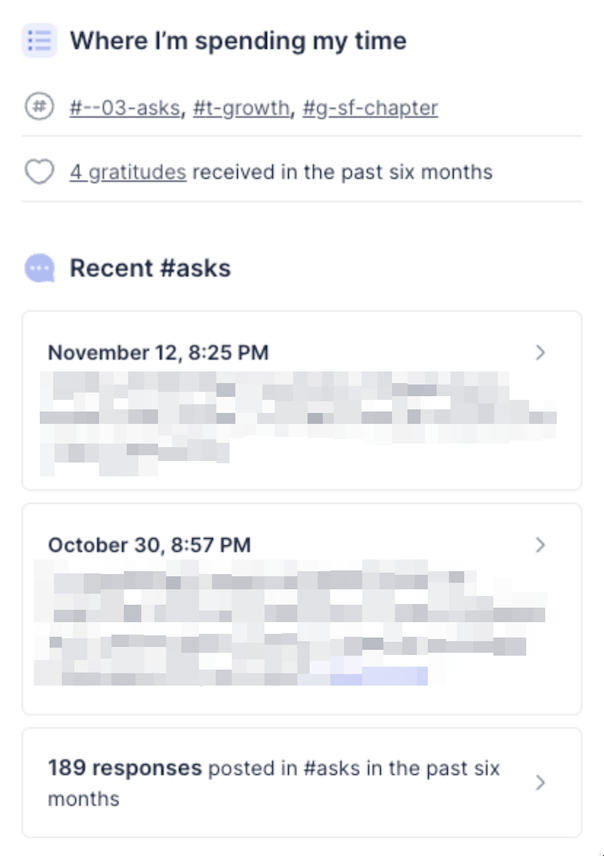
One of the most important elements of the Community Platform are user profiles, which can be used to find others to connect with by understanding their background, experience and current focus areas. However, in order for profiles to be valuable, information should be up to date. While you can ask users to update their profiles frequently, it’s better if you can minimize that and instead derive profile updates from their activity.
In order to do that, we’ve decided to utilize the Slack usage data and surface relevant data points from the last six months on users’ profiles, including
- top three public channels determined by number of user’s posts
- number of gratitudes received (in dedicated #gratitudes channels)
- two most recent asks posted
- number of responses in asks channels
Besides showing this information on the profile, we wanted to link to the relevant channels or posts.
3.1 Ingesting Slack activity into Snowflake
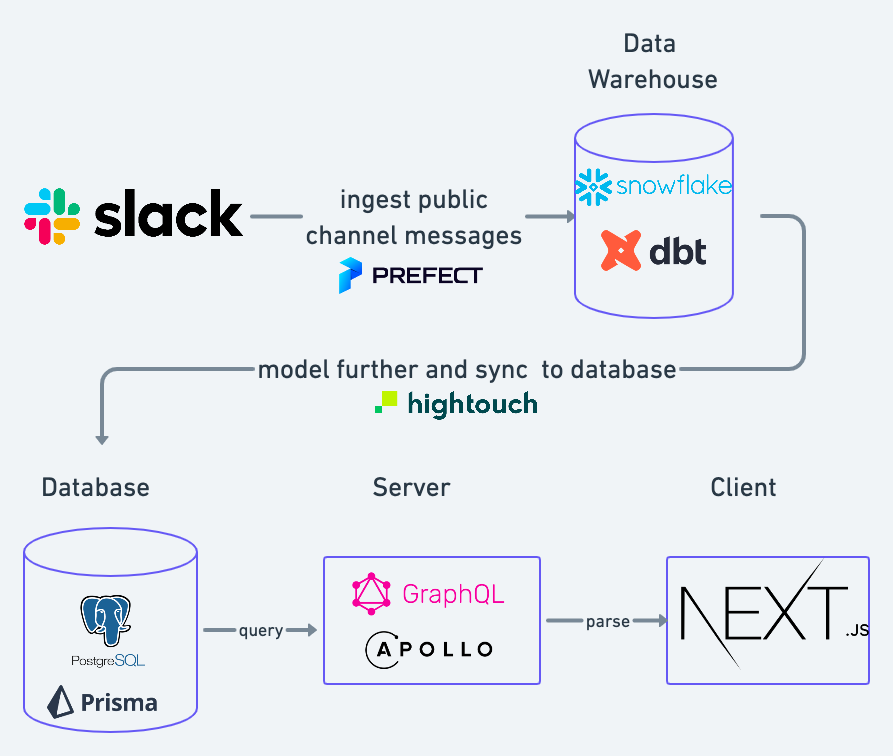
We’ve already been using Slack usage data for internal analysis and reporting. We’ve built a custom pipeline (which is orchestrated using Prefect) to ingest public channels Slack messages into our data warehouse (Snowflake). This involves several steps
- Use the Slack API to fetch messages from the channels
- Parse the messages, extract relevant information and transform it into a desired format
- Insert rows into relevant tables in Snowflake
3.2 Transforming data with dbt
All data we were looking for was in our public channels messages table in the domain layer. Finding relevant messages was slightly different depending on the needed data point. For example, to obtain all top-level posts in the asks channels, we’d filter the top-level posts from specified channels and exclude thread responses
with
slack_asks_posted as (
select
event_timestamp,
slack_workspace_id,
slack_conversation_name,
slack_msg_text,
slack_thread_ts,
slack_ts,
dmn_fellows.fellow_id,
dmn_fellows.name,
dmn_fellows.fellow_email,
dmn_fellows.slack_user_id,
dmn_fellows.image_url
from
dmn_slack_events
left join dmn_fellows
on sender_fellow_id = dmn_fellows.fellow_id
where
event_type = 'slack_public_channel_message'
and slack_conversation_id in ('C...', 'C...', 'C...') -- selected asks channels
and timediff(month, event_timestamp, current_timestamp()) <= 6 -- last 6 months
and (
slack_ts = slack_thread_ts
or slack_thread_ts is null
) -- top level posts only
)
select * from slack_asks_postedWe’ve created these tables in the presentation layer of our data pipeline (managed with dbt). They were not in the final format that would be required on the Community Platform but in a way where these tables could be re-used by others.
3.3 Modeling and syncing to Postgres with Hightouch
Since querying data directly from Snowflake can be risky, expensive and slow, we’ve had to find a different way to make it accessible on the server and/or client side. While there are some dedicated solutions to this (i.e. cube.dev), our use case was relatively simple so we’ve decided to sync it to our DB using Hightouch. The Hightouch model did some further parsing for key columns into JSON format. From then, we’ve synced it to our main PostgreSQL DB.
with
slack_channel_posts as (
select
fellow_id,
to_json(
array_agg(
object_construct(
'slack_conversation_id', slack_conversation_id,
'slack_conversation_name', slack_conversation_name,
'slack_workspace_id', slack_workspace_id,
'slack_workspace_name', slack_workspace_name,
'posts', posts
)
)
) as top_channels
from
ondeck_analytics.metabase.slack_channel_posts
group by
fellow_id),
slack_asks_posted as (
select
fellow_id,
to_json(
array_agg(
object_construct(
'slack_conversation_id', slack_conversation_id,
'slack_conversation_name', slack_conversation_name,
'slack_workspace_id', slack_workspace_id,
'slack_workspace_name', slack_workspace_name,
'slack_msg_text', slack_msg_text,
'event_timestamp', event_timestamp,
'slack_thread_ts', slack_thread_ts,
'slack_ts', slack_ts
)
)
) as asks_posted
from
ondeck_analytics.metabase.slack_asks_posted
group by
fellow_id),
slack_asks_responses as (
select
fellow_id,
to_json(
array_agg(
object_construct(
'slack_conversation_id', slack_conversation_id,
'slack_conversation_name', slack_conversation_name,
'slack_workspace_id', slack_workspace_id,
'slack_workspace_name', slack_workspace_name,
'slack_msg_text', slack_msg_text,
'event_timestamp', event_timestamp,
'slack_thread_ts', slack_thread_ts,
'slack_ts', slack_ts
)
)
) as asks_responded
from
ondeck_analytics.metabase.slack_asks_responses
group by
fellow_id),
slack_gratitudes as (
select
receiver_fellow_id as fellow_id,
to_json(
array_agg(
object_construct(
'slack_conversation_id', slack_conversation_id,
'slack_conversation_name', slack_conversation_name,
'slack_workspace_id', slack_workspace_id,
'slack_workspace_name', slack_workspace_name,
'slack_msg_text', slack_msg_text,
'event_timestamp', event_timestamp,
'slack_thread_ts', slack_thread_ts,
'slack_ts', slack_ts
)
)
) as gratitudes_received
from
ondeck_analytics.metabase.slack_gratitudes
group by
fellow_id),
joined as (
select
coalesce(
slack_channel_posts.fellow_id,
slack_asks_posted.fellow_id,
slack_asks_responses.fellow_id,
slack_gratitudes.fellow_id
) as fellow_id,
coalesce(
slack_channel_posts.fellow_id,
slack_asks_posted.fellow_id,
slack_asks_responses.fellow_id,
slack_gratitudes.fellow_id
) as fellow_id_number,
slack_channel_posts.top_channels,
slack_asks_posted.asks_posted,
slack_asks_responses.asks_responded,
slack_gratitudes.gratitudes_received
from
slack_channel_posts
full outer join slack_asks_posted
on slack_asks_posted.fellow_id = slack_channel_posts.fellow_id
full outer join slack_asks_responses
on slack_asks_responses.fellow_id = slack_channel_posts.fellow_id
full outer join slack_gratitudes
on slack_gratitudes.fellow_id = slack_channel_posts.fellow_id
)
select joined.*
from joined inner join fivetran_db.directory_live_public.fellow f on f.id = joined.fellow_id
where joined.fellow_id is not null and f._fivetran_deleted = falseSince this was a first proof of concept, we’ve decided against a more robust on write schema in order to make the iterations easier and faster. Since the amount of activity data per user was relatively small, enforcing schema on read was not a blocker in the context of performance.
3.4 Parsing JSON columns on the server
We use Prisma to manage our DB and Apollo to run our GraphQL server. Since JSON columns aren’t typed in Prisma, we’re parsing and validating data incoming from the DB using yup in order to ensure type safety on the client side and to fail gracefully in case of any inconsistencies in JSON formatting.
// resolver
export default async function slackActivity(
fellow: Fellow,
_args: unknown,
ctx: Context
): Promise<FellowSlackActivity | null> {
if (!couldSeeSlackActivitiesAndInitiatives(ctx)) {
return null;
}
return ctx.batchLoad(BATCH_KEY, fellow.id, async (fellowIds) => {
const rows = await ctx.prisma.fellowSlackActivity.findMany({
where: {
AND: [{ fellowId: { in: [...fellowIds] } }],
...filterByMutualProgramOrAdmin(ctx),
},
});
const packed = packOneToOneNullable(fellowIds, rows, (row) => row.fellowId);
const parsed = packed.map((row) => {
if (!row) {
return null;
}
const {
fellowId,
asksPosted,
asksResponded,
gratitudesReceived,
topChannels,
} = row;
return {
...row,
fellowId: fellowId.toString(),
asksPosted: parseAsksPosted(asksPosted, ctx),
asksResponded: parseAsksResponded(asksResponded, fellow, ctx),
gratitudesReceived: parseGratitudesReceived(
gratitudesReceived,
fellow,
ctx
),
topChannels: parseSyncedSlackChannels(
topChannels,
ctx,
maxNumberOfTopChannels
),
};
});
return parsed;
});
}
// sample corresponding parsing util and yup schema
const parseSyncedSlackChannels = (
channels: Prisma.JsonValue,
ctx: Context,
limit?: number
): SyncedSlackChannel[] | null => {
if (!(Array.isArray(channels) && channels.length)) {
return null;
}
const sortedChannels = orderBy(channels, "posts", "desc");
const channelsToParse = limit
? sortedChannels.slice(0, limit)
: sortedChannels;
const parsedKeyChannels = channelsToParse.map((channel) =>
objectKeysToCamelCase(channel)
);
const validChannels = parsedKeyChannels.filter(isSyncedSlackChannel);
if (validChannels.length) {
return validChannels.map((channel) => ({
...channel,
url: getChannelUrl(channel, ctx),
}));
}
return null;
};
const syncedSlackChannelSchema = yup.object({
slackConversationId: yup.string().required(),
slackConversationName: yup.string().required(),
slackWorkspaceId: yup.string(),
slackWorkspaceName: yup.string().required(),
posts: yup.number().required(),
});One area that turned out to be a bit more complex than expected was the logic around URL to original Slack content. One key requirement was to ensure that we only show links to content that the viewer has access to in Slack. This wasn’t straightforward since users can have access to multiple workspaces and global channel messages were still mapped to the workspace through which the original message was sent. We’ve had to make some assumptions here based on the programs that users were part of and their corresponding workspaces.
Another important consideration was the UX. There are a few types of ways to deep link into Slack, i.e.
- link to Slack web app - opens the channel or message directly (no extra clicks required) - this requires being logged in via the browser
- link to Slack native app - this doesn’t require being logged in via the browser but requires having a native client installed
- redirect link that prompts opening the channel/message in Slack native app, but also allows opening it in web UI (one extra click required) - this requires being logged in via the browser
There are downsides to each of these and unfortunately not all options are possible across all types of content such as channel, post and search query.
We’ve decided to use redirect links where possible (since it allows opening in native app and in the browser) and to use links to the Slack web app as a back up for gratitude and asks responded links, since we’ve had to link to Slack UI with the search query pre-populated and executed. In case of the search query links, it turned out that the queries are base64 and URL encoded so we needed a util to parse the queries accordingly.
const getGratitudesReceivedSearchUrl = (
gratitudeReceived: SyncedSlackPost[],
fellow: Fellow,
ctx: Context
): string | null => {
if (!fellow.slackId) {
return null;
}
const { matchingWorkspaceId, uniqueConversationIds, meSlackId } =
getSlackSearchQueryParams(ctx, gratitudeReceived);
if (!matchingWorkspaceId) {
return null;
}
const query = {
q: meSlackId,
r: encodeURI(
[
...uniqueConversationIds.map((id) => `in:<#${id}>`),
`<@${fellow.slackId}>`,
].join(" ")
),
};
const encodedQuery = Buffer.from(JSON.stringify(query)).toString("base64");
return encodedQuery
? `https://app.slack.com/client/${matchingWorkspaceId}/search/search-${encodedQuery}`
: null;
};3.5 Surfacing Slack activity data on user profiles
Finally, on the client side we query the GQL server and show this information. Almost all of the logic is managed on the server so the client side doesn’t need to deal with privacy and visibility settings, sorting the relevant channels or messages and generating Slack links.
4. How can you leverage Slack data?
We’ve received some really positive feedback on this feature, from both internal and external users. Our team members use this profile info to get additional context on fellows when interacting with them. Our community members are able to learn more about where other users are spending time, what things they might need help with (which encourages reciprocity when reaching out with a personal ask) or how helpful of a community member they might be.
This was also the first time where we’ve closed the loop between our data warehouse and the user facing product. The more usage we have, the more data we have in the warehouse, which in turn benefits the user facing product.
Slack usage has been an important in assessing the user engagement and informing future product decisions, such as productizing asks on the Community Platform. With the new Slack activity feature on profiles we’ve been able to empower our users to engage with the rest of the community while having a direct view into those patterns.
More broadly, being able to query Slack usage data through SQL and our analytics tools, has been a major unlock for the entire team.
If you’re using Slack, or any other external tool as part of the core experience for your community, I’d strongly recommend going beyond the basics analytics offered by those messaging tools. Don’t let it become a black box and use it to supercharge your existing and future product development.